
同一只腾讯7种写法,AI Agent该信谁?

QVeris · 数据实测
从一只港股代码的 7 种写法说起——AI 金融助理最容易栽跟头的地方,不是模型,是 ticker。
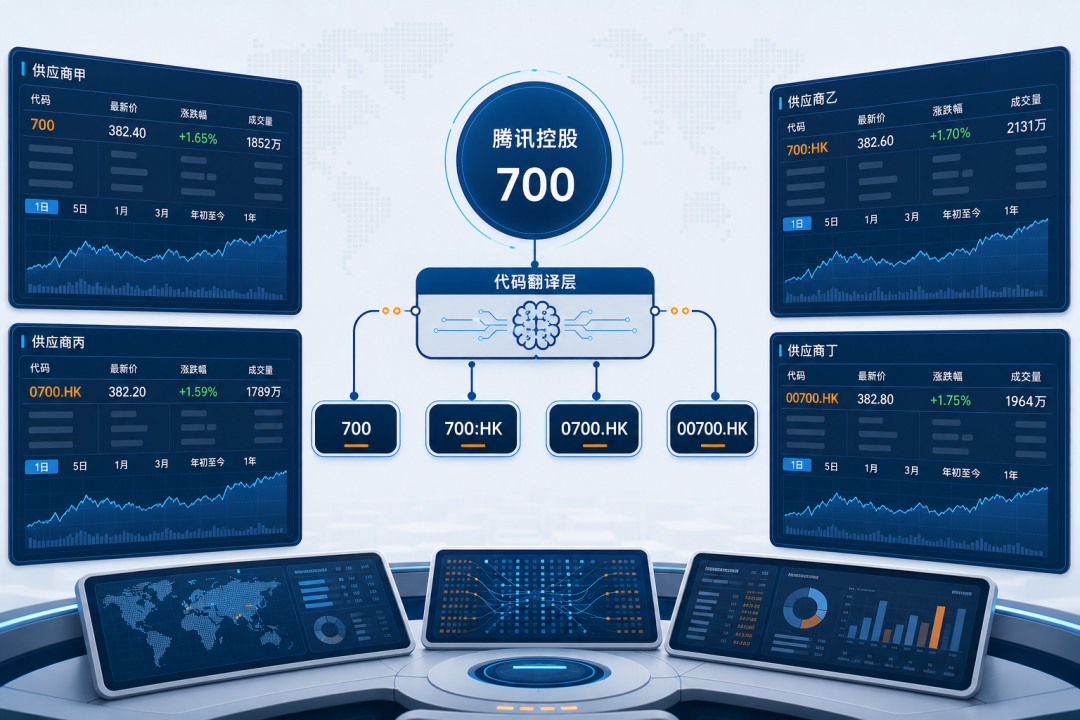
图 1: Hero — 腾讯控股 700 + 代码翻译层多终端总览
同一只腾讯,主流付费数据源里有 7 种写法
如果你让一个 AI 助理帮你查"腾讯今天涨了多少",它该用哪种 ticker 去问数据源?我们去翻了一圈各家付费机构终端的官方文档:
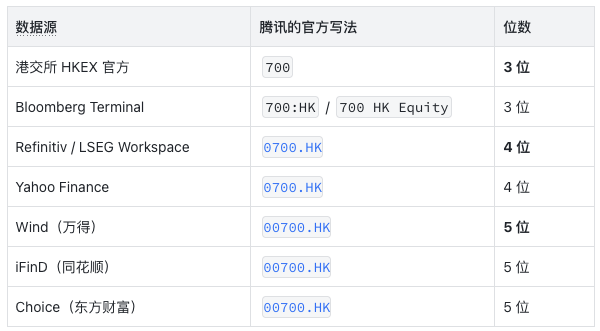
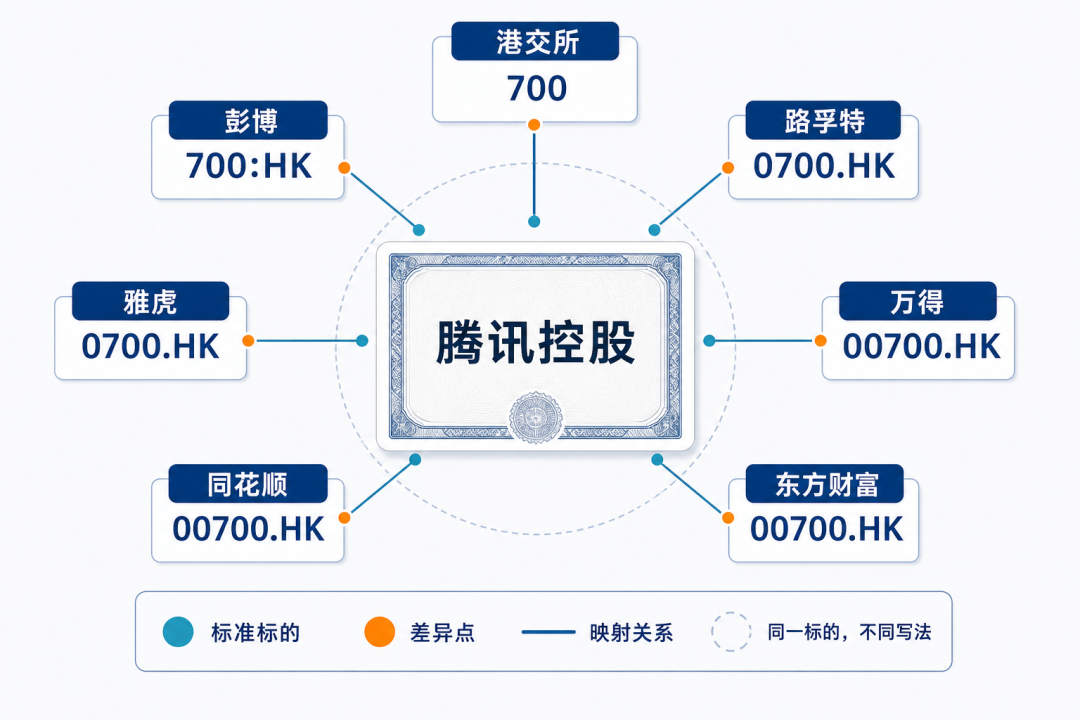
图 2: 腾讯控股 7 家供应商方言放射图
**
**
没有任何两个体系是完全一致的。
港交所自己用 3 位裸数字。Bloomberg 沿用裸数字加交易所代码。Refinitiv 早年定 RIC(Reuters Instrument Code,路透通用代码)的时候补到 4 位,成了大部分欧美机构的标准。万得在国内市场建立时再往左补一位 0 变成 5 位——这样 A 股的 600519.SH(6 位)和港股的 00700.HK(5 位)视觉上对齐。
每一家都有自己的历史原因。但对一个 AI Agent 来说,这就是 4 个完全不同的字符串。
A 股看起来更刺激。同样一只贵州茅台(600519),主流付费源给出的写法是这样:
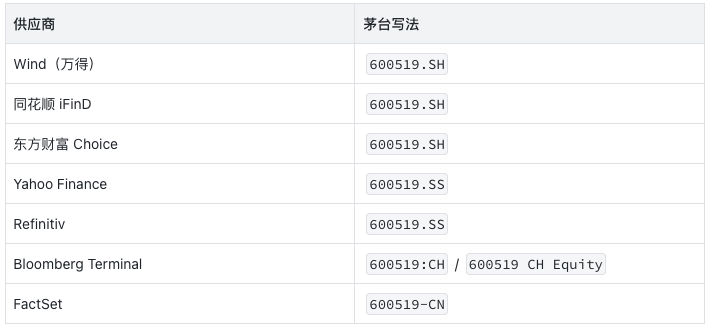
国内三家在 A 股口径上意外达成一致——都用 .SH。但一到海外数据源,Yahoo 和 Refinitiv 改成 .SS,Bloomberg 改成 :CH,FactSet 用连字符加 -CN。
你在国内市场看着以为统一了,到了海外数据源就发现根本不是一回事。
Agent 不是查错了,是供应商之间互相听不懂
这种"方言"问题,远比"Agent 编了个数"更隐蔽。
行业里最常见的一种做法,是给每个市场写一个代表性 ticker——CN → 600519.SH,HK → 0700.HK,然后用这套全局表去探测每一个供应商的能力。能查到,就标"支持这个市场";查不到,就标"不支持",缓存几十天。
接下来会发生什么?
好几家国际付费数据源会被冤枉成"不支持 A 股"——它们不是不支持,而是它们说 A 股的方言是 .SS 或 :CH,不是 .SH。同一个接口,把 .SH 改成 .SS 再试一次,茅台 ¥1330+ 完整的 K 线数据全数返回。同一家供应商再用 0700.HK 查港股、用 7203.T 查日股、用 SAP.DE 查德股、用 PETR4.SA 查巴西股、用 AAPL 查美股——全部都能跑通。**
**
它完全覆盖亚太+欧洲+南美的主流市场,只是没人告诉过它你说的是哪种 ticker 方言。
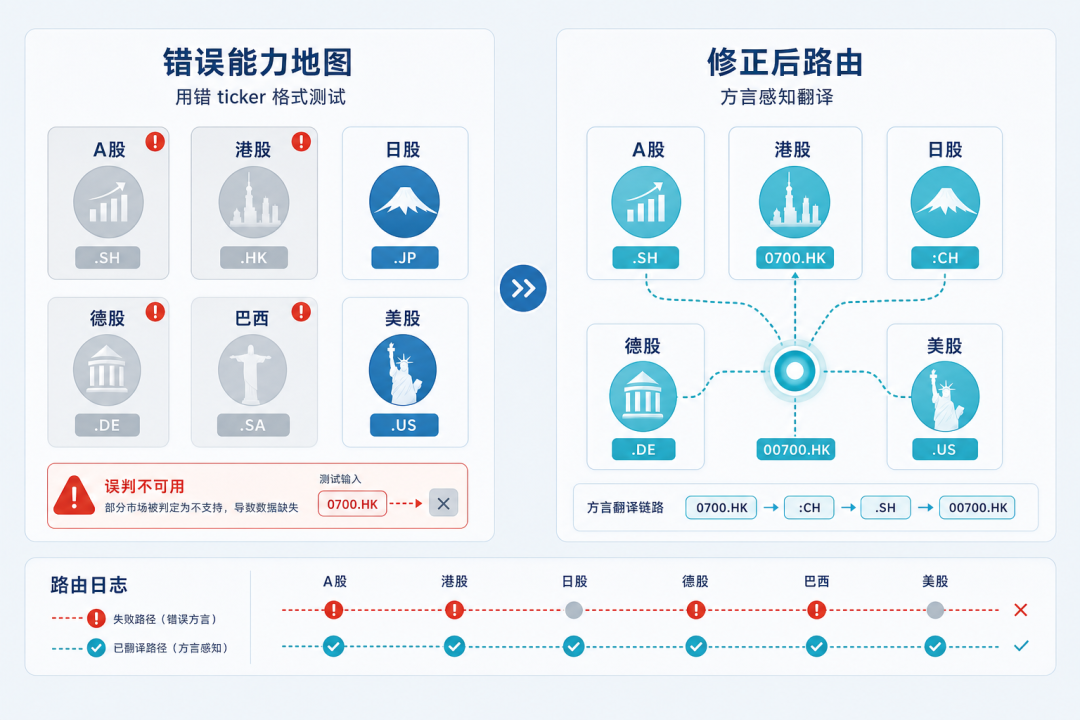
图 3: 错误能力地图 vs 修正后路由对照
这种"冤枉"在 Agent 时代的代价远大于人类时代。
一个分析师如果发现某个终端查不到 A 股,他会换种方式再试试,或者打电话问客服。Agent 不会——它信你给它的那张能力地图。地图标"该供应商不支持 A 股",它就再也不去问了。被冤枉的供应商越多,它能用的数据源就越少,最后它只能用剩下的少数几家凑活——或者,更糟,基于训练数据里的记忆,编一个看起来合理的答案给你。
V2EX 上有人列过三个 Agent 翻车的真实案例:一个 Agent 把 24 小时累计成交量当成单根 K 线的成交量,量级差了几千倍;一个在 API 限流后陷入重试死循环,两分钟烧光一天的 Token 配额;一个在工具调用失败后模型不报错,基于参数化记忆编了一个看起来合理的价格。2025 年 3 月还有金融机构的 AI 客服因为生成虚假理财产品信息,导致客户单笔损失超过 500 万。
这些故事看起来五花八门,根都在同一处——Agent 与工具之间,缺一层"翻译"。
我们最近做的"方言翻译层"
过去一个月,QVeris团队在工具调用底座上合并了 35 个 PR,做的不是新功能,是给"Agent → 工具"这条链路补一层方言翻译。
这层翻译有三件事要做:
第一件,自动识别市场。 你扔过来一个 ticker,无论它是 600519 还是 0700 还是 AAPL,先判断它属于哪个市场。这是路由的前提——不知道是哪国股票,就不知道该路由给谁。
第二件,给每个供应商建一份"方言档案"。我们用每个供应商对每个市场的最小可调用样例做实测——这家供应商在 A 股说什么口音、那家供应商在港股说什么口音、第三家供应商在巴西股说什么口音。这些不是抄文档抄来的,是真调一次接口、真返回数据后存档的。文档会过时,实测不会。 这份档案在我们内部叫"供应商方言表",会随着每一轮调用自动 self-heal。
第三件,调用前自动转方言。Agent 给我们一个 ticker(比如 600519.SH),我们根据它要去的供应商,在路由层自动把它翻译成那家供应商听得懂的方言——去 Yahoo / Refinitiv 转成 600519.SS,去 Bloomberg 转成 600519:CH,去 FactSet 转成 600519-CN,去 Tushare 去掉后缀变 600519。Agent 不需要知道这层翻译存在,就像你打越洋电话不需要懂海底光缆。
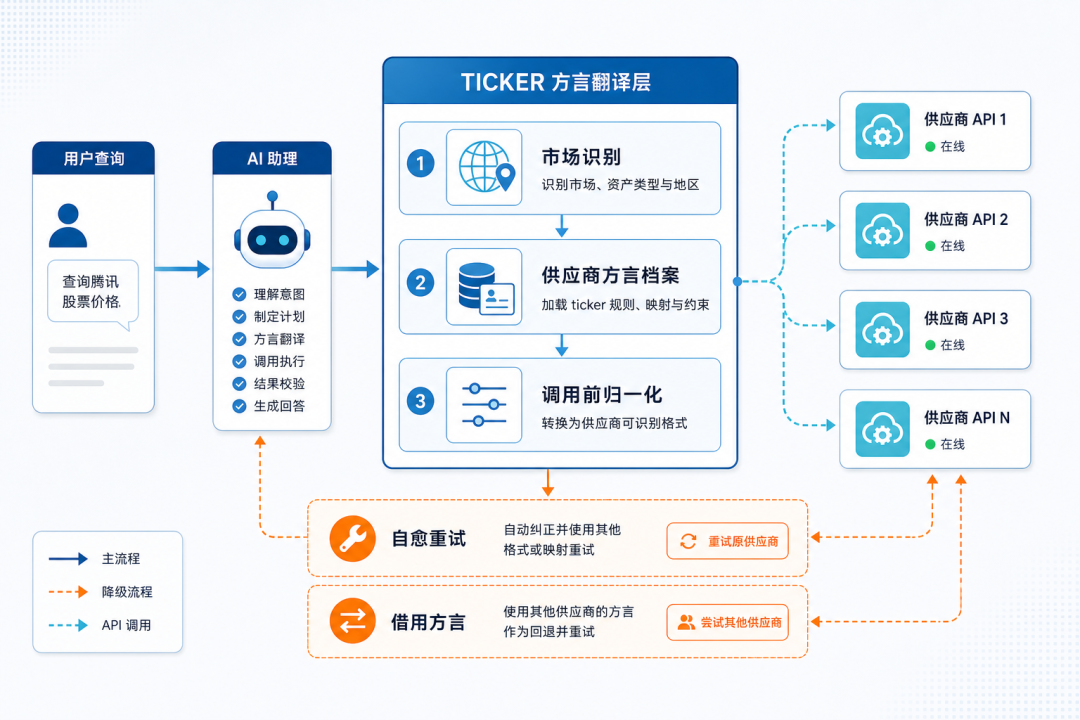
图 4: TICKER 方言翻译层架构(用户→AI→三步→供应商 API + fallback)
为这三件事兜底的还有一层 fallback——当某个"供应商 × 市场"的组合还没有方言档案时,用跨供应商借用 + 方言归一引擎现场翻译。最不济才回落到全局常量。四层降级,每一层都有数据驱动的依据。
这套东西做完之后,我们看到的不是"调用成功率涨了多少"——那种数字宣传材料里都能写。我们看到的是之前被方言冤枉的供应商陆续平反——A 股、港股、日股、巴西股的覆盖,一个一个地从"被认为不支持"回到"实际可用"。

图 5: 查到了 / 猜到了 / 没听懂 三态对照
腾讯今天涨幅接近 7%。但这只是 ticker 海里最干净的那一只。还有改名股、退市股、停牌股、复权调整、单位歧义——每一个都是 Agent 翻车点,每一个都需要一层"翻译"。
下次你的 AI 助理告诉你某只股票的实时价格,请记得问它一句:
你查到了,还是猜到了?还是——它根本没听懂你说的是哪只腾讯?
**
**