
从一次失败的工具调用开始:让 Agent 学会自动修复参数

QVeris · 技术实践
背景
QVeris 已经把大量 API 和工具接入到 Agent 的执行链路中,让模型可以真实地访问数据、调用服务、完成任务。
随着工具被更高频的使用,一个新的问题开始变得越来越重要:
Agent 不只是要能调用工具,还要能在调用失败时理解原因、修正参数,并尽可能保持用户原始意图继续完成任务。
真实场景里的工具调用失败并不罕见。
很多时候并不是工具本身不可用,也不是用户用错了,而是用户自然表达、模型生成参数、以及 provider 标准定义之间存在细小但关键的差异。
比如,用户可能只是想查某只股票、某个日期范围、某类指标,但不同 provider 对参数格式的要求并不完全一样:
-
股票代码是否需要 .SH / .SZ 这样的市场后缀
-
多个代码应该传数组,还是逗号分隔字符串
-
日期字段叫 startdate/enddate,还是 from/to
-
必填字段是否必须显式传入
-
某些指标字段是否只接受 provider 自己定义的枚举值
-
某些数据源是否对权限、地区、标的范围有限制
这些差异对工具调用来说非常关键。Agent 如果不能理解并修正这些差异,就可能出现"意图是对的,但参数没对齐"的失败。
真实世界里的用户意图和 provider 的可执行 schema 之间,需要一个可靠的对齐层。
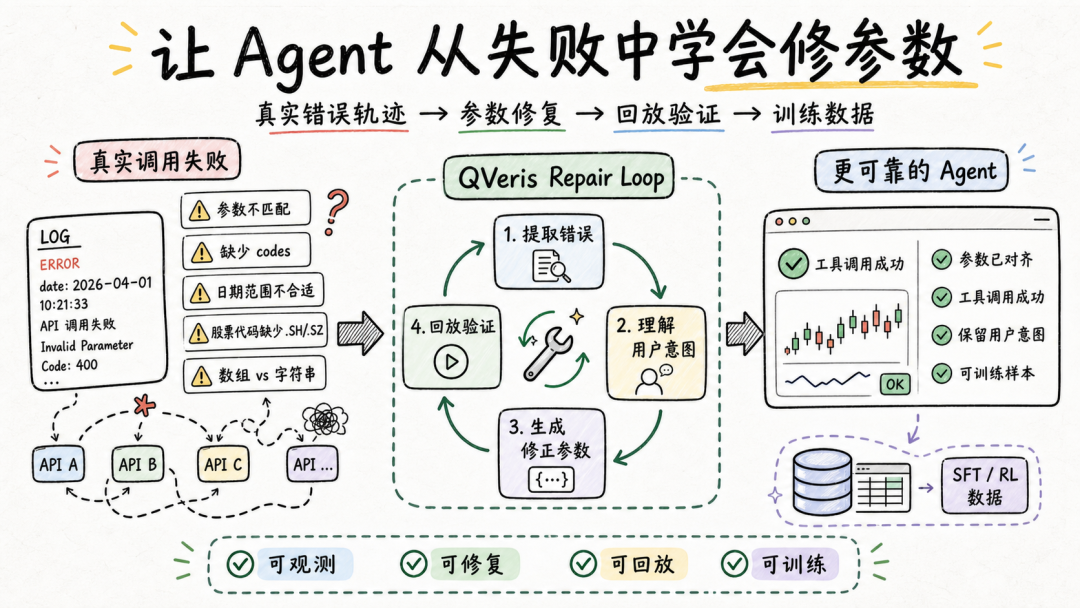
所以我最近在做的事情,就是把这些调用失败记录整理成一套可分析、可回放、可训练的数据链路,让系统能从真实错误中学习,逐步提升工具参数修复能力。
我们在做什么
一条完整的参数修复轨迹大概是这样的:
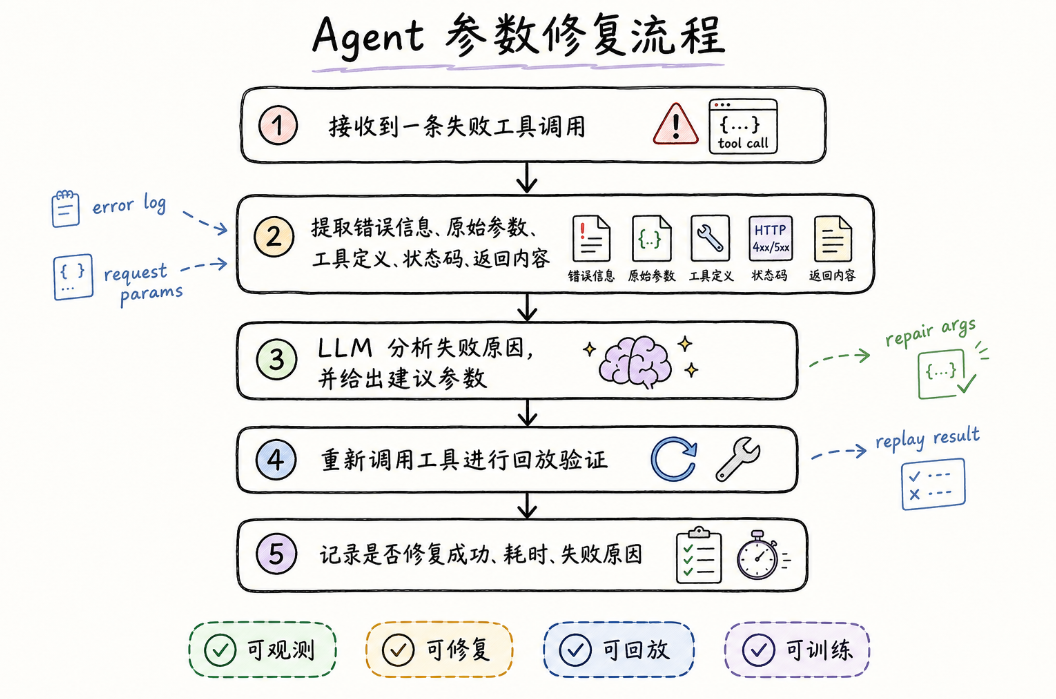
这条链路看起来简单,但真正做起来会遇到很多细节问题。
真实工具调用日志通常非常复杂:里面既有用户意图、原始参数,也有工具定义、状态码、provider 返回结果、错误信息和执行上下文。对 Agent来说,并不是把整条日志原封不动塞进去就能解决问题,关键是要从中提炼出真正有助于修复的上下文。
比如一次调用失败后,模型需要同时看到:
-
用户最初想查什么
-
实际传给工具的参数是什么
-
工具定义中要求的字段名和字段类型是什么
-
provider 返回的错误信息是什么
-
是否存在权限、资源、数据范围等外部限制
只有这些信息被组织清楚,模型才有可能判断:
这次失败到底是字段缺失、格式不匹配、参数值不合适,还是 provider 本身的数据范围或权限限制。
这也说明,Agent 参数修复并不只是让模型再想一次,而是要建立一套面向工具执行的上下文整理机制。
真实例子:行情工具的错误归因
以一个实时行情工具为例,我们对真实失败记录做了聚类分析。
这里不是提前人工定义错误类型,而是按照真实出现的错误文本进行归类。这样可以更接近线上实际情况。
我们看到的错误包括:
API error: no data.Too many codes: maximum allowed is 50Ambiguous codes found缺少必需的查询参数Permission deniedServer disconnected
这些错误背后的修复方式并不一样。
比如:
-
Too many codes说明一次传入的证券代码超过上限,需要截断或分批 -
Ambiguous codes说明代码不够明确,需要补齐市场后缀 -
缺少必需参数说明字段名可能传错了,或者模型没有补齐必填字段
-
Permission denied则为权限或数据源限制,不应该简单算作普通参数修复失败 -
API error: no data可能需要结合标的、日期、指标字段进一步判断 -
这类分析帮助我们把失败记录拆成更细的可处理问题。
一次小规模实验
我们选取了一批真实的行情工具失败记录,做了一轮参数修复实验。
流程很直接:
失败记录 -> 关键信息提取-> LLM 分析原因 -> 给出修正参数 -> 重新执行验证
实验中可以看到,模型已经能识别出不少典型问题,比如:
-
缺少必填参数
-
股票代码缺少市场后缀
-
一次传入的代码数量超过工具限制
-
参数字段名和工具定义不一致
-
某些错误其实更接近权限或数据源限制
更有意思的是,很多失败并不是因为模型完全不理解问题,而是卡在了更细的工具格式约束上。
例如,用户可能只是想查 600519.SH 和 000001.SZ 的行情。这个意图本身很清楚,但当 LLM 把它转换成工具参数时,就需要严格匹配provider 的参数格式。
对于某些行情工具来说,多个股票代码需要被组织成一个英文逗号连接的字符串:
{"codes":"600519.SH,000001.SZ"}
而不是 JSON 数组:
{"codes":["600519.SH","000001.SZ"]}
这两种写法在语义上都表达了多个代码,但对工具来说是完全不同的数据类型。
这说明参数修复不只是语义理解问题,也是工具 schema 对齐问题。
Agent 要真正可靠地使用工具,不能只知道应该查哪些股票,还要知道:
字段名该叫什么字段类型是什么多个值该怎么表达哪些后缀是 provider 能识别的哪些错误不应该继续靠参数修复解决
这也给后续优化提供了一个很明确的方向:在 prompt 和工具定义压缩中,不仅要告诉模型这个工具能做什么,还要更清楚地告诉它这个工具希望参数长什么样。
从"能跑通"到"保留用户意图"
这轮实验还带来一个很重要的判断:参数修复不应该只是换一个能成功的参数,而应该尽量保留用户原始意图。
比如用户原来想查一组证券代码,如果错误是代码缺少市场后缀,正确修复应该是补全后缀,而不是直接换成一个常见样例代码。
后者可能能跑通,但它没有保留用户意图。
因此后续在对 agent 提供的 prompt 设计应该明确:
先读取用户原始参数再根据错误信息判断问题尽量保留原始查询标的最后严格按工具 schema 输出修复参数
只有在完全无法恢复原始意图时,才使用高覆盖 fallback 示例。
为什么这件事重要
如果系统只是失败后返回一段错误文本,Agent 的体验就会中断。
但如果系统能理解错误、修复参数、重新执行,那 Agent的能力就从"会调用工具"变成了"能处理工具调用失败"。
工具调用只是第一步。真正决定 Agent 能否进入生产环境的,是它在复杂工具生态里的执行可靠性。
QVeris 正在做的,就是把调用、反馈、修复和验证串成一个持续进化的闭环。