
金融 AI 不只要会回答,更要可验证

QVeris · 产品测评
金融 AI 最危险的地方,不是答不上来,而是答得很像真的,却说不清数据从哪来。
在金融场景里,一段分析要进入真实业务流程,不能只看语言是否流畅,还要看它:
能不能给出具体数值,
能不能标明数据时间点,
能不能留下可追溯来源,
能不能在公告、行情、事件监控、异常检测这些复杂任务里稳定产出可用答案。
这正是 QVeris 的关键能力。
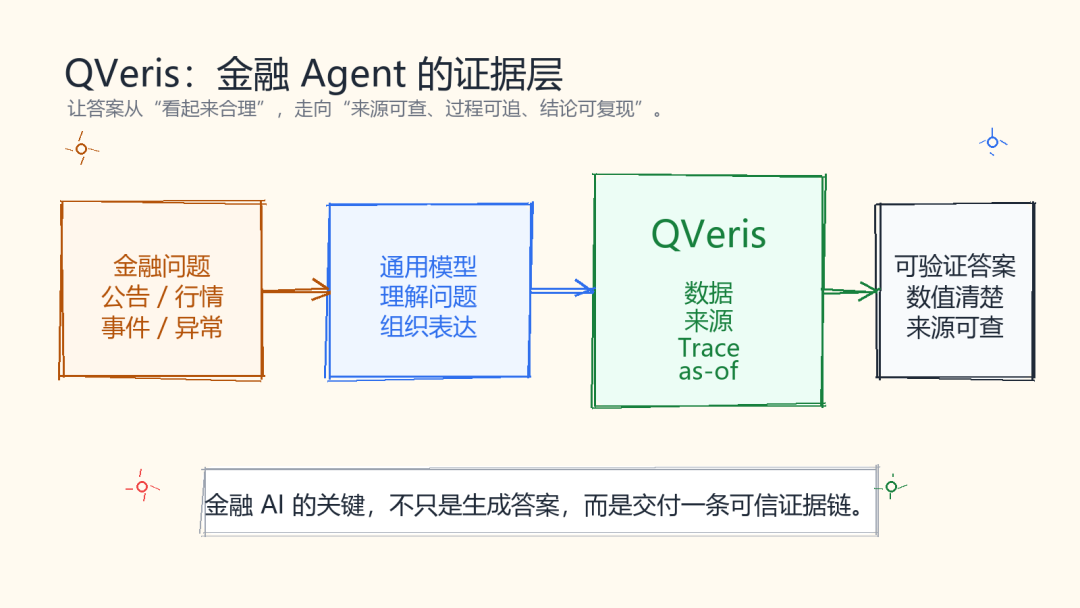
本次测评以 Claude 作为控制 Agent,覆盖 50 个真实金融工作流任务,比较三种运行方式:
-
不接入 QVeris 的 baseline、
-
通过 QVeris CLI 接入的 qveris-cli,
-
通过 QVeris MCP 接入的 qveris-mcp。
任务覆盖金融信息检索、市场数据查询、公告摘要、事件监控、异常发现和多源整合等典型场景。评分由 DeepSeek deepseek-v4-pro 作为 LLM Judge 完成。
接入 QVeris 后,Claude 金融任务得分显著提升
本次测评结果很直接:接入 QVeris 后,Claude 在金融任务上的平均得分从 70.78 提升到 82 分以上;其中 qveris-mcp 达到 83.76,是三组最高。
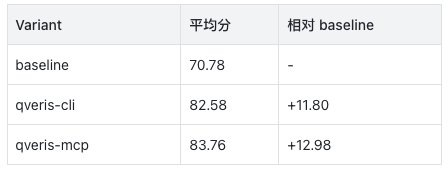
换句话说,在同一个 Claude 控制 Agent 下,QVeris 让金融任务平均得分提升约 12 到 13 分。
这不是单点指标的提升,而是整体工作流质量的提升。qveris-mcp 的完成率达到96%,有效结果率达到 94%,平均工具调用数只有 18.00 次,明显低于 baseline 的 45.26 次和 qveris-cli 的 26.90 次。
这说明 QVeris 不只是让 Agent 多了一个数据接口,而是让它用更短路径完成更高质量的金融分析。
QVeris 的核心价值,是补上金融 Agent 的证据链
通用大模型已经很会组织语言。真正的差距在于:它给出的金融结论是否可信、可查、可复现。
本次测评把 Trust 单独设为 25 分,关注来源质量、URL、as-of 时间、工具调用证据和反幻觉能力。五维指标拆开后,QVeris 的优势非常清楚。
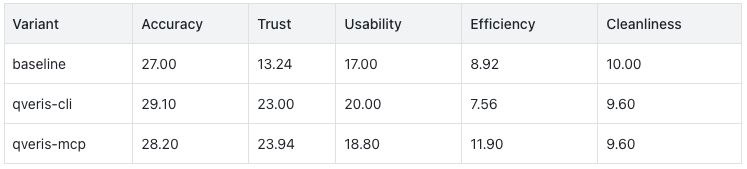
baseline 的 Accuracy 并不差,Cleanliness 甚至最高。这说明 Claude 本身已经具备较强的金融常识和文本组织能力。
真正拉开差距的是 Trust。
baseline 的 Trust 是 13.24,qveris-cli 是 23.00,qveris-mcp 是 23.94。
QVeris 解决的不是"AI 能不能写一段金融分析",而是"这段分析有没有可信来源、有没有工具证据、有没有可复现的调用链"。
MCP 接入让 Agent 更容易用好金融工具
在三种运行方式里,qveris-mcp 的综合表现最好。它不只是得分最高,也更省工具调用。
qveris-mcp 平均工具调用数为 18.00,低于 qveris-cli 的 26.90;平均 QVeris 调用数为 8.58,约为 qveris-cli 的一半。它的平均延迟也最低,为 907,640 ms;工具成功率达到 71.33%,高于 qveris-cli 的 62.34%。
这背后体现的是接口形态的差异。
CLI 更像是让 Agent 自己拼命令、试参数、处理文本输出;
MCP 则提供了更结构化的工具接口。
对 Agent 来说,结构化接口意味着更少误用、更短路径和更低调用成本。
因此,qveris-mcp 能在总分、完成率、有效结果率和效率上同时领先。
公告摘要和异常检测,是 QVeris 的高价值场景
从任务类型看,QVeris 在公告摘要、异常检测和多源整合任务上表现突出。
baseline 在事件监控和异常检测上并不弱,说明通用模型配合公开来源,能处理一部分开放信息任务。但公告摘要任务差距非常明显:baseline 只有 41.9,qveris-mcp 达到 79.0。
这类任务天然依赖稳定的数据入口、完整文档内容和清晰来源链。只靠公开网页搜索,容易遇到入口不稳定、内容不完整、引用不清楚的问题。
QVeris 的价值,正是在这些高要求任务中体现出来:让 Agent 不只是"搜到一些网页",而是通过专业数据和工具链拿到可验证材料。
在异常检测任务上,qveris-mcp 也达到 92.9,高于 baseline 的 84.9 和 qveris-cli 的 91.1。
这说明 QVeris 不只适合查询数据,也适合支持更复杂的金融判断流程。
这次测评对 baseline 是公平的
本次评分没有把"是否使用 QVeris"作为直接加分项。baseline 只要提供权威公开来源、URL 和 as-of,也可以拿到高 Trust 分。
同时,QVeris trace 也不是天然加分。只有当工具调用成功、证据可追溯、并且对答案有实际贡献时,才会带来可信度优势。
换句话说,QVeris 的领先不是因为评分规则偏心,而是因为它在金融任务中提供了更稳定、更可验证的数据和工具证据。
这套评分逻辑并非追求"完全中性",而是偏向可验证证据链。对金融任务来说,这是合理的价值取向。
金融分析里,只说"我认为"不够。能说明"我基于什么数据、什么时间点、什么工具调用得出结论",才是更接近生产可用的答案。
QVeris 的价值已经在结果中体现
任何面向真实金融场景的工具链,都需要持续打磨稳定性、覆盖率和接入体验。QVeris 也一样,它仍会继续演进。
但从本次测评结果看,QVeris 的价值已经非常清楚:显著提升了金融 Agent 的可信度、完成率和业务可用性。尤其是 qveris-mcp,在总分、完成率、有效结果率和工具效率上都取得了最好的综合表现。
这意味着 QVeris 不只是一个"数据接口",而是在帮助 Agent 建立更可靠的金融分析工作流:从提出问题,到获取数据,再到形成可追溯结论。
对金融 AI 来说,这种从语言生成到证据驱动的转变,是迈向生产可用的关键一步。
最终判断:QVeris 让金融 Agent 更接近真实业务可用
本次测评可以得到三个明确判断。
第一,如果看最终质量,qveris-mcp 当前最好。它的总分最高,完成率最高,有效结果率最高,调用效率也最好。
第二,如果看答案完整性和结构可用性,qveris-cli 很强。它的 Accuracy 和 Usability 表现突出,适合需要更强结构化输出的场景。
第三,baseline 表现合格,但短板明显。它成本低、输出干净,但在金融证据链、公告摘要和数据源可追溯性上仍然落后。
QVeris 的核心价值可以概括成一句话:它让金融 Agent 从"能写出答案",走向"能给出可验证、可追溯、可进入业务流程的答案"。
这正是金融 AI 从 demo 走向生产时必须跨过的一道门槛。
通用大模型解决的是语言能力,而 QVeris 补上的,是金融场景最需要的那一层:数据、证据、工具链和可复现性。
这也是 QVeris 在金融 Agent 时代最值得被看见的价值。